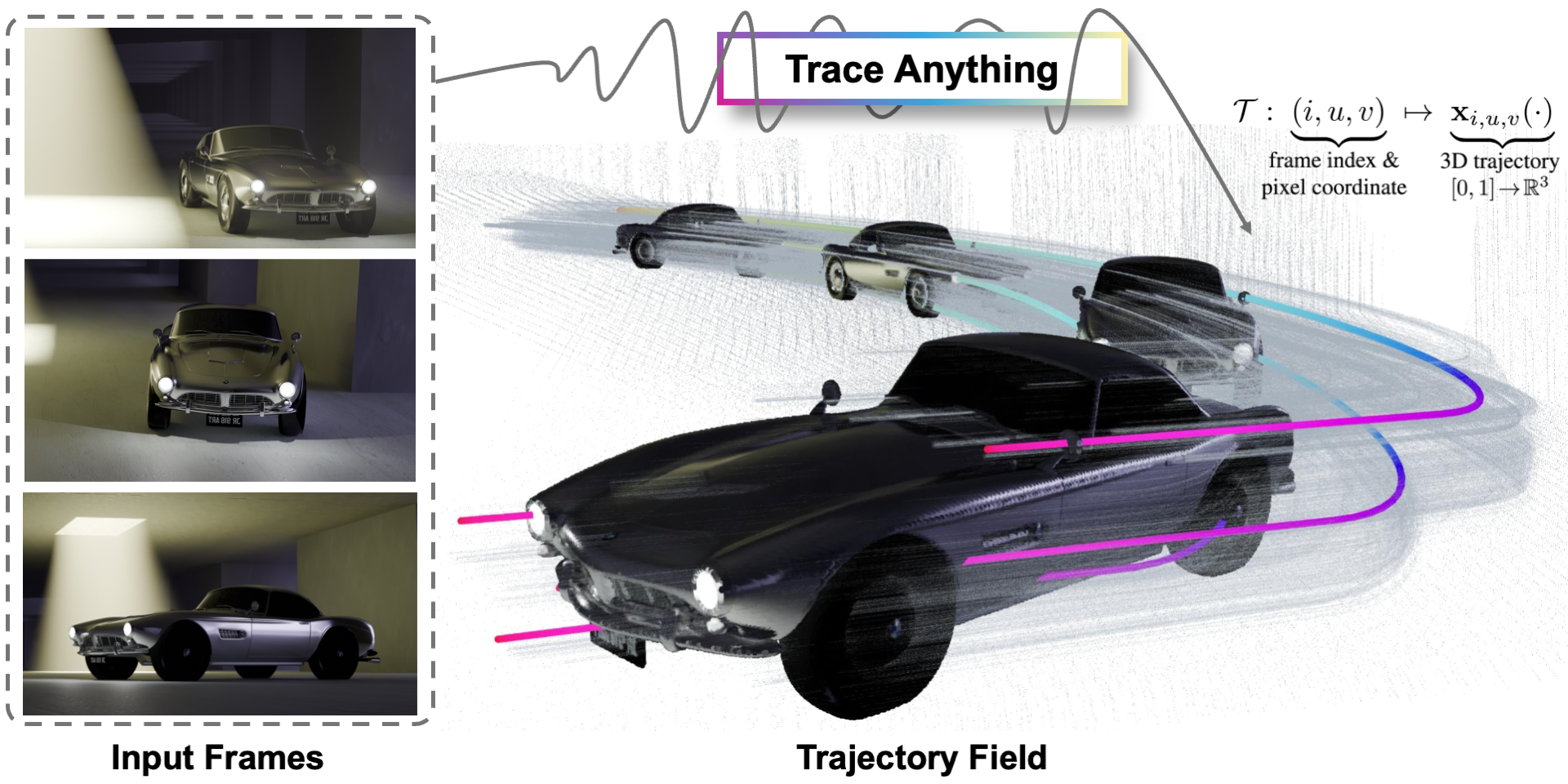
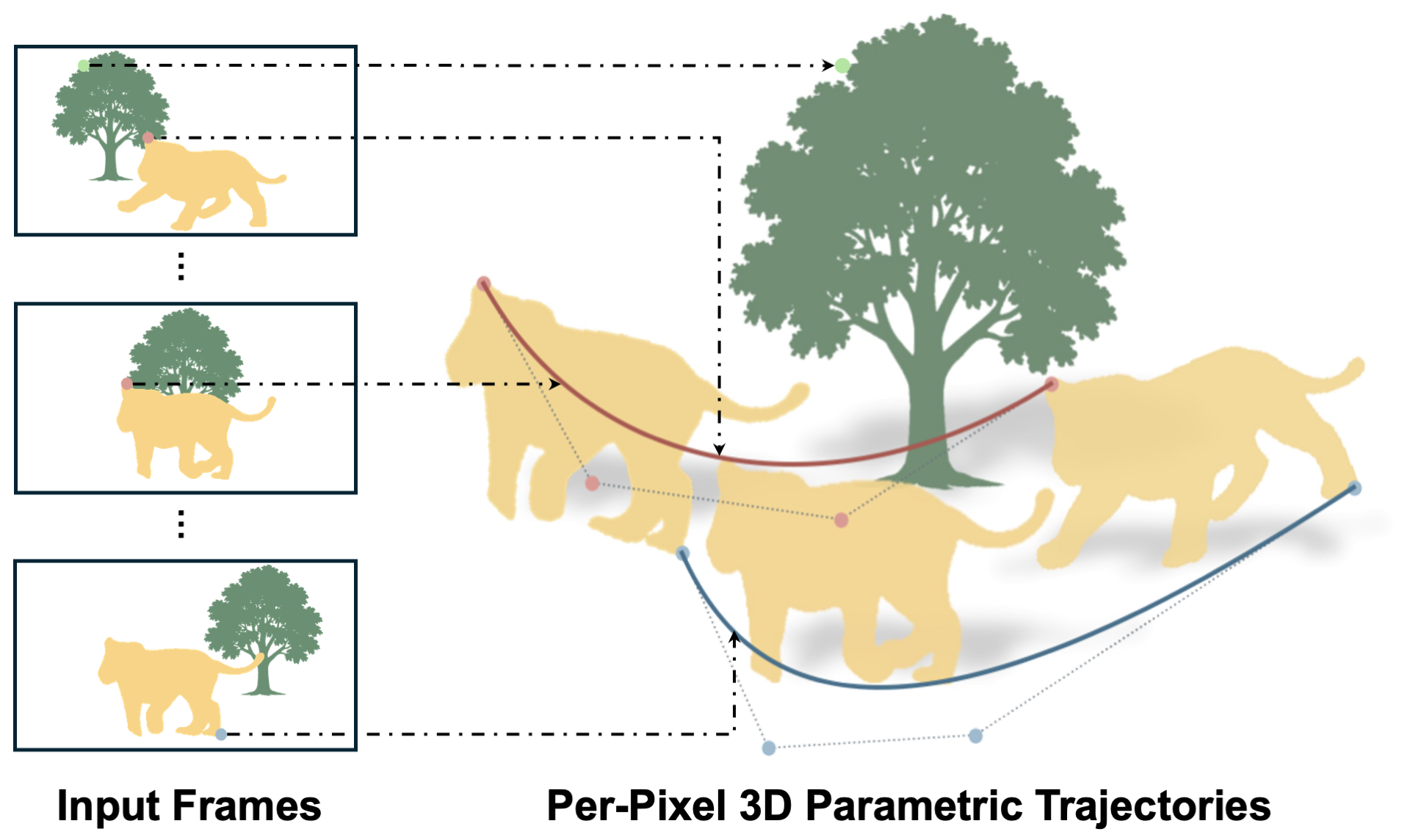
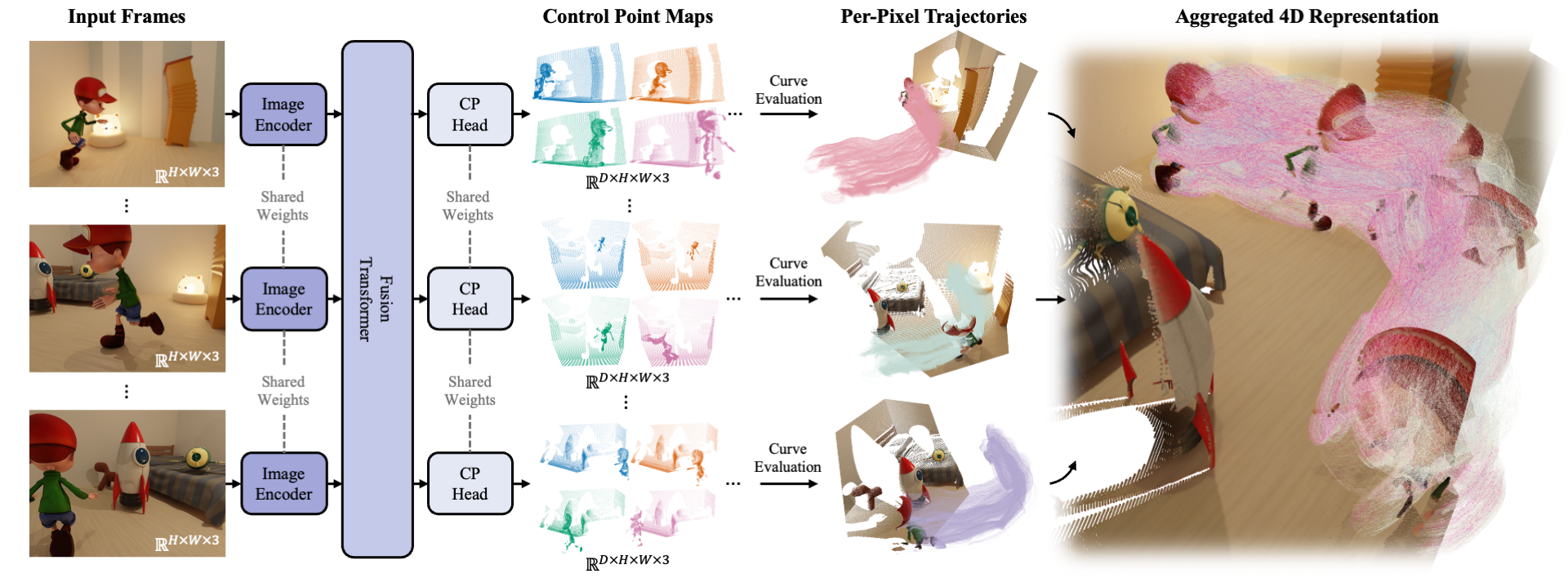
Abstract
Effective spatio-temporal representation is fundamental to modeling, understanding, and predicting dynamics in videos. The atomic unit of a video, the pixel, traces a continuous 3D trajectory over time, serving as the primitive element of dynamics. Based on this principle, we propose representing any video as a Trajectory Field: a dense mapping that assigns a continuous 3D trajectory function of time to each pixel in every frame. With this representation, we introduce Trace Anything, a neural network that predicts the entire trajectory field in a single feed-forward pass. Specifically, for each pixel in each frame, our model predicts a set of control points that parameterizes a trajectory (i.e., a B-spline), yielding its 3D position at arbitrary query time instants. We trained the Trace Anything model on large-scale 4D data, including data from our new platform, and our experiments demonstrate that: (i) Trace Anything achieves state-of-the-art performance on our new benchmark for trajectory field estimation and performs competitively on established point-tracking benchmarks; (ii) it offers significant efficiency gains thanks to its one-pass paradigm, without requiring iterative optimization or auxiliary estimators; and (iii) it exhibits emergent abilities, including goal-conditioned manipulation, motion forecasting, and spatio-temporal fusion.